
A lurking variable sometimes called a hidden or unobserved variable, is not included in the analysis but still affects the relationship between the variables being studied. Ignoring such variables can lead to misleading or even completely wrong conclusions.
In statistical research and data analysis, our main goal is to understand the relationship between variables. We want to find out how one factor influences another—whether a drug reduces symptoms, whether exercise improves mental health, or whether more advertising leads to higher sales. But sometimes, these relationships are not as straightforward as they seem.
A third, hidden variable might be quietly influencing the results. This unseen factor is known as a lurking variable.
Table of contents
Defining the Lurking Variable
A lurking variable is a variable that:
- Has a significant impact on the outcome (response variable),
- Is not included in the analysis or model,
- Influences the relationship between the variables being studied,
- Can create the illusion of causality when none exists or obscure a real one.
This differs from a confounding variable, which is included or known in the analysis but still interferes with our understanding of the true relationship.

Public, Onsite, Virtual, and Online Six Sigma Certification Training!
- We are accredited by the IASSC.
- Live Public Training at 52 Sites.
- Live Virtual Training.
- Onsite Training (at your organization).
- Interactive Online (self-paced) training,
Example of Lurking Variable
You might notice that students who bring umbrellas to school tend to do worse on tests. Does carrying an umbrella cause bad grades? No—the weather (rain) is the lurking variable. It might cause stress, distractions, or other conditions that influence test performance. Since it’s not part of the analysis, it lurks in the background, quietly distorting results.
Also Read: What is Variable Data?
Origins and Importance in Statistical Thought
The concept of lurking variables gained recognition through the work of statisticians such as George Box, John Tukey, and W. Edwards Deming. Their work in industrial quality control and experimental design highlighted the dangers of drawing conclusions without considering all possible factors.
In particular, Walter A. Shewhart, the father of statistical process control, observed that even carefully gathered laboratory data often had unexplained variability. By examining data over time and identifying unexpected shifts or patterns, he was able to detect “assignable causes”—often lurking variables affecting the process.
This approach became the foundation of diagnostic data analysis, encouraging analysts to be skeptical of surface-level relationships and to probe deeper into what might be missing from their models.
How Lurking Variables Distort Relationships?
When a lurking variable exists, it can:
- Create a false association between variables,
- Hide a true relationship,
- Reverse the apparent effect (as seen in Simpson’s Paradox),
- Exaggerate or weaken the actual effect.
Let’s break down these effects with more examples.
A. False Association
Example: Ice cream sales and drowning incidents often rise and fall together. One might mistakenly believe eating ice cream causes drowning.
Reality: The lurking variable is temperature. Hot weather leads to more people swimming (increasing drowning risk) and also more people buying ice cream. The true driver is the season, not a causal link between the two behaviors.
B. Hidden Real Relationship
Sometimes, a true causal relationship exists, but the lurking variable makes it appear weaker or even nonexistent.
Example: Suppose researchers study how a new teaching method affects math scores, and they see no improvement. However, if the students using the new method come from under-resourced schools, and those using the old method are from better-funded ones, the effects of teaching style may be masked. School funding is the lurking variable influencing the outcome.
C. Simpson’s Paradox
Simpson’s Paradox occurs when a trend that appears in different groups of data disappears or reverses when the groups are combined. This paradox often reveals the presence of a lurking variable.
Example:
| Treatment | Success | Failure | Success Rate |
| A | 100 | 100 | 50% |
| B | 110 | 80 | 57.9% |
At first, Treatment B looks better. But split by gender:
Males:
| Treatment | Success | Failure | Success Rate |
| A | 60 | 20 | 75% |
| B | 100 | 50 | 66.7% |
Females:
| Treatment | Success | Failure | Success Rate |
| A | 40 | 80 | 33% |
| B | 10 | 30 | 25% |
Now, Treatment A looks better for both genders. The gender variable wasn’t initially considered—it was lurking. When accounted for, the interpretation of the data completely changes.
Detecting Lurking Variables
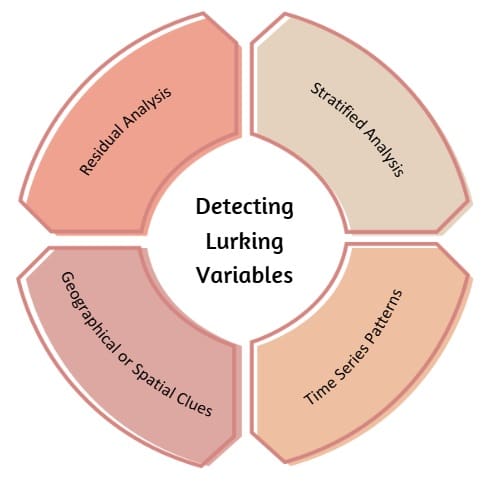
Identifying lurking variables is challenging because, by definition, they’re not included in the analysis. However, there are clues and techniques that help uncover them:
A. Residual Analysis
By examining the residuals (the difference between observed and predicted values), we can look for patterns. If residuals show non-random structure (e.g., a wave or cluster), this might suggest that something else—possibly a lurking variable—is influencing the data.
B. Stratified Analysis
Breaking data into subgroups (like age, gender, location) can reveal hidden trends. If relationships differ across groups, a lurking variable may be influencing the results.
C. Time Series Patterns
Examining data across time can uncover hidden patterns. For instance, if product defects increase every Monday, maybe a lurking variable like weekend maintenance is at play.
D. Geographical or Spatial Clues
When analyzing data collected from different places, local factors may act as lurking variables. For example, air pollution data across cities might be affected by altitude, industrial activity, or traffic density.
Also Read: Binomial Random Variable
Controlling Lurking Variables
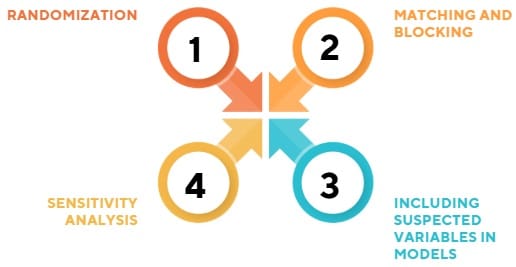
While you can’t always detect every lurking variable, there are strategies to minimize their effects:
A. Randomization
In experiments, randomly assigning subjects to groups ensures that lurking variables (known or unknown) are evenly distributed across treatment groups. This minimizes their impact and strengthens causal claims.
B. Matching and Blocking
In observational studies, subjects can be matched based on characteristics like age, income, or location. This controls for those variables by ensuring comparisons are made between similar individuals.
C. Including Suspected Variables in Models
When a potential lurking variable is known or suspected, including it in the statistical model allows its effect to be accounted for directly.
D. Sensitivity Analysis
Analysts can test how results change under different assumptions. If small changes in assumptions lead to big changes in outcomes, this suggests that lurking variables may be influencing the data.
Lurking Variables in Observational vs. Experimental Studies
A. Observational Studies
These studies observe existing behaviors or conditions without interference. While practical and often necessary (e.g., in ethics-sensitive fields like medicine), observational studies are more prone to lurking variables because the researcher cannot control conditions.
Example: A study finds that people who drink red wine live longer. However, those who drink red wine may also be wealthier, eat healthier, and have better healthcare access—factors not always included in the analysis.
B. Experimental Studies
These involve controlled interventions and random assignments, which help eliminate or reduce lurking variable effects. For instance, drug trials use randomization and blinding to ensure that neither patients nor doctors influence outcomes based on their expectations or biases.
Also Read: Key Process Input Variable (KPIV)
Real-World Impact of Ignoring Lurking Variables
Public Policy Mistakes
Policies based on misleading data can backfire. For example, if crime rates drop in cities with more police officers, we might assume that police presence causes the drop. However, if these cities also invest in community programs (a lurking variable), then police presence alone might not be the key factor.
Medical Misinterpretation
A study might show that a new drug works better than an old one. But if healthier patients were more likely to receive the new drug, patient health is a lurking variable, not the drug itself.
Business Strategy Flaws
A company might notice that when they spend more on marketing, sales go up. But maybe this only happens during the holiday season—time of year is the lurking variable.
Correlation Does Not Imply Causation
One of the most important lessons in statistics is this: correlation does not imply causation. Two variables may move together, but without understanding lurking variables, we can’t be sure that one causes the other.
Ignoring lurking variables is one of the biggest reasons why incorrect conclusions are drawn from correlated data. The presence of such variables can reverse the direction of an observed trend or make it disappear entirely when proper adjustments are made.
Final Thoughts
Lurking variables are the invisible threads that often pull the strings in data relationships. While they are elusive and sometimes impossible to fully identify, researchers and analysts can:
- Think critically about what might be missing from their data,
- Use sound design principles like randomization and stratification,
- Examine residuals and patterns carefully,
- Avoid drawing strong conclusions from observational data alone,
- Always question causality, even when the data seems clear.
By being aware of lurking variables, we become better analysts, scientists, and decision-makers—more careful, more skeptical, and ultimately, more accurate.

















